


Hello Everyone,
Here I'm with my Hashnode API Hackathon Project "HashCraft".
HashCraft enables you to write a blog on Hashnode, and then conveniently convert it into an ebook or PDF document. This allows writers to publish their content on other platforms such as Google Play Books and Kindle.
Moreover, HashCraft also caters to readers by allowing them to have a local copy of the blog. This feature proves useful in scenarios with limited or unreliable internet access, as it permits users to access and read content offline. Additionally, having a local copy offers readers a personal archive of blogs they find interesting.
Story Behind Building HashCraft!!
Let's go back in time to when I used to read technical articles and referred to them for learning new technology from others.
During my college days, I was following a nice blog tutorial series on Python Django for my college project. The series consisted of a step-by-step tutorial on Django, and as a beginner, I found it promising and helpful for learning and implementing the concepts for my college project.
Due to personal reasons, I had to go to a remote place (my village). There, I encountered network issues, which were devastating for me since my college project submission was approximately two weeks away, and it was not ready yet. Because of the network problems, I was unable to access the blogs or even watch YouTube videos. Since Django was a completely new tech stack for me, I depended on blogs more due to their simplicity in explaining concepts.
Personally, I prefer reading blogs, books, and documentation over watching videos because, many times, I find that reading saves time – a simple reason!
Now, what happened? Did I submit my college project on time? The answer is yes. I tried my best, wrapped up my work from the remote place, and came back to my hometown where I had a proper network connection.
But that day, I thought if I could have a local file or something similar for the Django Tutorial Blog series, things could have been better for me, and I wouldn't have had to rush.
And from a Blog Reader point of view I got this idea to create a PDF doc using Hashnode Blog.
Let's consider it from a writer's point of view. As a writer, there are often instances when we aspire to compile our blogs into a book. I've observed that many individuals on Hashnode produce outstanding blog series. With the help of this application, they can effortlessly create an ebook or PDF document. This document can then be published on platforms such as Google Play Books or Kindle. Furthermore, they have the option to publish a hardcopy without the need to leave Hashnode.
Write your blog Once on Hashnode and Publish it as Ebook Anywhere
Demo
Here we go and let's see how we can create ebook and pdf doc using HashCraft.
For this demo I will be using one amazing blog by Mayank Aggarwal on React 🚀. Since I've started learning React lately again and found this blog helpful from Beginner-Intermediate standpoint.

Just copy the link to the blog and paste it on HashCraft.

Click on Load button and let the magic happen
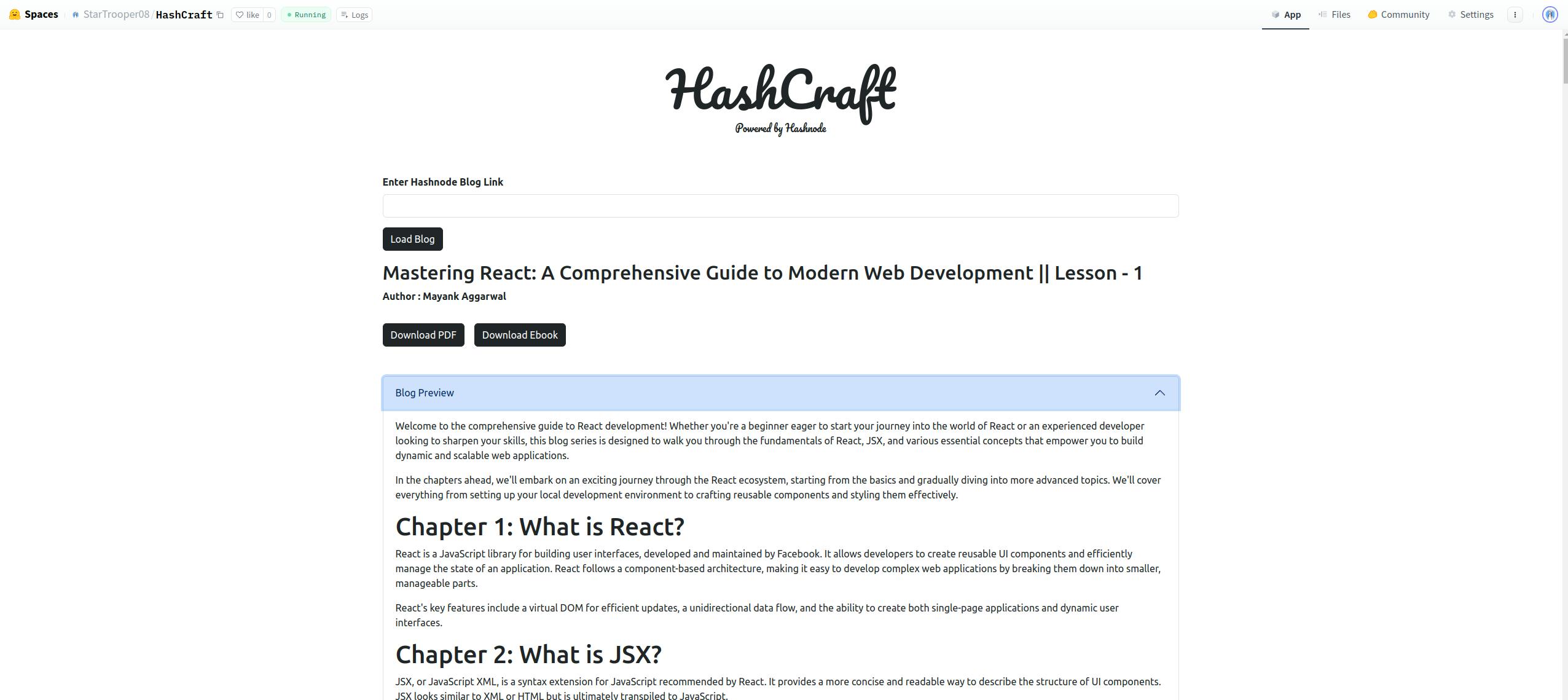
The App shows the Blog Title, Author Name and we can also preview the blog.
After that we can download PDF doc version or Ebook version of the blog whichever we want. Let's try downloading both versions for this React Blog.
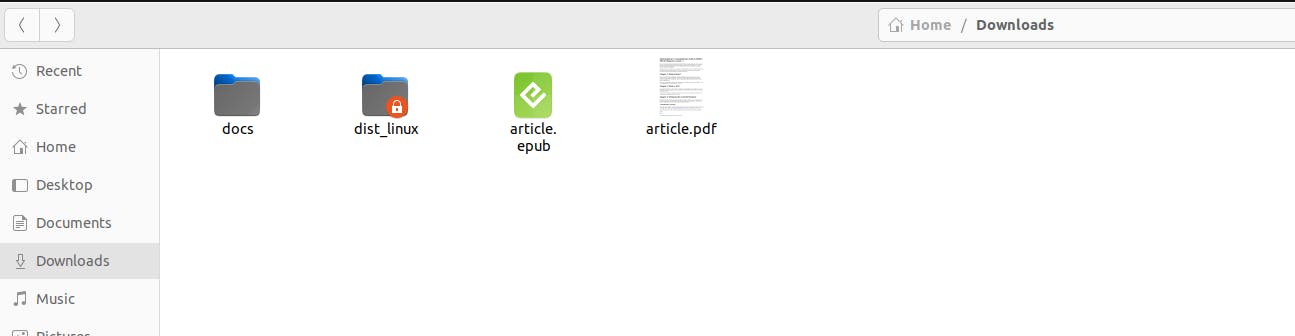
I have downloaded both pdf doc and ebook(epub) version for this demo. Let's view content using the respective supported tools.
PDF Viewer :
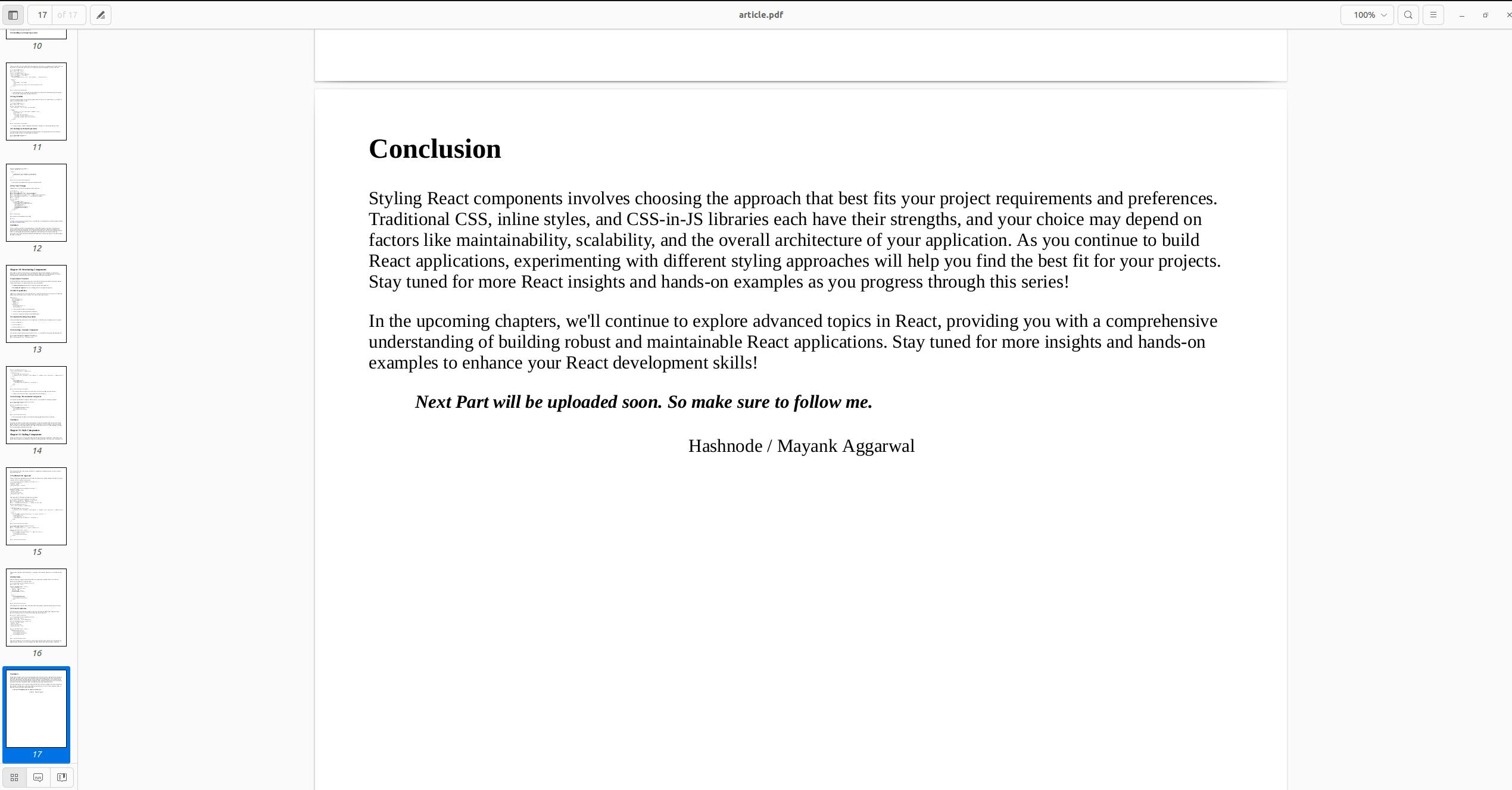
First page :

Last page : The last page has Author Name
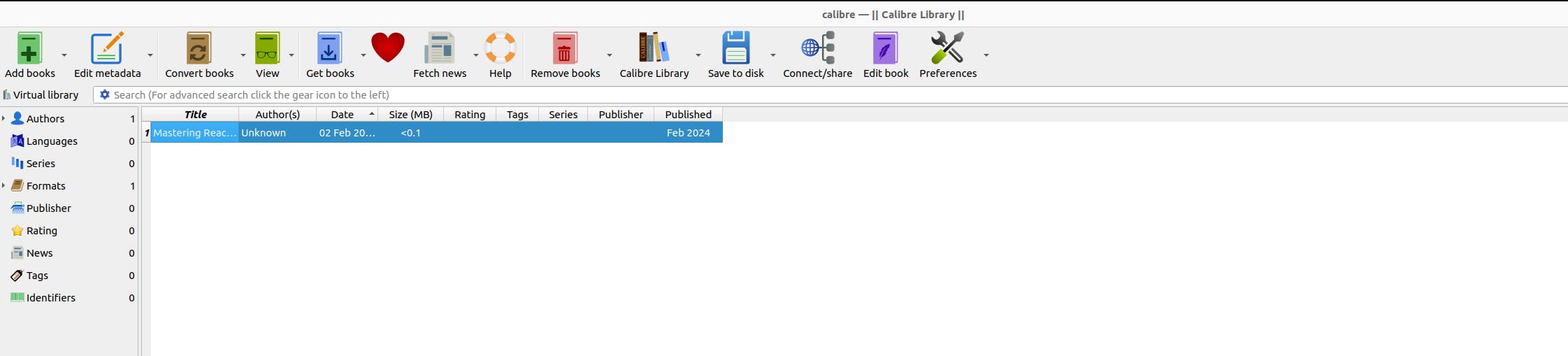
Calibre Ubuntu(For Ebook):
I have added the ebook to Calibre book collection.
When we click on View button we can see the title of the book on frontpage.

After clicking the -> arrow we can see the main content

Google Play Books
We can also view the ebook on Android mobile using Google Play Books or Kindle.


Project Breakdown
Tech Stack :
Flask(pyhtml2pdf), Bootstrap, Hashnode Graphql API, Pandoc
For Deployment : Docker and Hugging face Spaces
Fetch Graphql API
Here I have fetch the data using requests module. The hashnode link is splitted in 2 part host and slug which is putted in the query.
def fetch_html_content(host, slug):
url = "https://gql.hashnode.com/"
query = f"""
query Publication {{
publication(host: "{host}") {{
post(slug: "{slug}") {{
title
content {{
html
}}
author {{
name
}}
}}
}}
}}
"""
data = {"query": query}
response = requests.post(url, json=data)
if response.status_code == 200:
result = response.json()
title = result.get("data", {}).get("publication", {}).get("post", {}).get("title", "")
author_name = result.get("data", {}).get("publication", {}).get("post", {}).get("author", {}).get("name", "")
html_content = result.get("data", {}).get("publication", {}).get("post", {}).get("content", {}).get("html", "")
return title, author_name, html_content
else:
print(f"GraphQL request failed with status code {response.status_code}: {response.text}")
return None, None, None
def extract_host_and_slug(blog_link):
parts = blog_link.split("/")
host = parts[2] if len(parts) > 2 else ""
slug = parts[3] if len(parts) > 3 else ""
return host, slug
Create HTML file and Remove emojis
After fetching blog data in html form. We need to save it on html file for further process. The emojis are removed since the pandoc doesn't supports and renders emojis properly.
def create_html_file(html_content):
html_filename = "output.html"
with open(html_filename, "w", encoding="utf-8") as html_file:
html_file.write(html_content)
return html_filename
def remove_emojis(html_content):
emoji_pattern = re.compile("["
"\U0001F600-\U0001F64F"
"\U0001F300-\U0001F5FF"
"\U0001F680-\U0001F6FF"
"\U0001F700-\U0001F77F"
"\U0001F780-\U0001F7FF"
"\U0001F800-\U0001F8FF"
"\U0001F900-\U0001F9FF"
"\U0001FA00-\U0001FA6F"
"\U0001FA70-\U0001FAFF"
"\U00002702-\U000027B0"
"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
cleaned_html = emoji_pattern.sub('', html_content)
return cleaned_html
Conversion from HTML to PDF and Ebook
This functions converts HTML to Ebook and PDF doc. And also adds author name in footer and title in header to pdf and ebook(author name is not added here).
def convert_html_to_pdf(title, author_name, html_filename, pdf_filename):
# Use the title as header in the PDF
header_html = f"<h1>{title}</h1>"
# Combine the header HTML and the existing HTML content
full_html = header_html + open(html_filename, "r", encoding="utf-8").read()
# Add footer only on the last page
footer_html = f'<div style="text-align: center; margin-top: 20px;">Hashnode / {author_name}</div>'
full_html += footer_html
# Save the combined HTML to a temporary file
temp_html_filename = "temp_output.html"
with open(temp_html_filename, "w", encoding="utf-8") as temp_html_file:
temp_html_file.write(full_html)
# Convert the combined HTML to PDF
converter.convert(f'file:///{os.path.abspath(temp_html_filename)}', pdf_filename, install_driver=False)
# Remove the temporary HTML file
os.remove(temp_html_filename)
def convert_html_to_epub(title, html_filename, epub_filename):
# Use subprocess to call Pandoc for HTML to EPUB conversion
subprocess.run(['pandoc', html_filename, '-o', epub_filename, '--metadata', f'title={title}'])
# Remove the temporary HTML file
os.remove(html_filename)
Flask Routes
Here I've created 3 routes home, download-pdf and download-ebook. The convert_pdf and convert_epub calls the convert html to pdf function and convert html to epub function respectively.
@app.route('/', methods=['GET', 'POST'])
def index():
host = ""
slug = ""
title = ""
author_name = ""
html_content = ""
if request.method == 'POST':
blog_link = request.form['blog_link']
host, slug = extract_host_and_slug(blog_link)
title, author_name, html_content = fetch_html_content(host, slug)
return render_template('index.html', host=host, slug=slug, title=title, author_name=author_name, html_content=html_content)
@app.route('/convert_pdf', methods=['POST'])
def convert_pdf():
host = request.form['host']
slug = request.form['slug']
title, author_name, html_content = fetch_html_content(host, slug)
cleaned_html = remove_emojis(html_content)
html_filename = create_html_file(cleaned_html)
pdf_filename = "article.pdf"
convert_html_to_pdf(title, author_name, html_filename, pdf_filename)
if os.path.exists(html_filename):
os.remove(html_filename)
return send_file(pdf_filename, as_attachment=True)
@app.route('/convert_epub', methods=['POST'])
def convert_epub():
host = request.form['host']
slug = request.form['slug']
title, _, html_content = fetch_html_content(host, slug)
cleaned_html = remove_emojis(html_content)
html_filename = create_html_file(cleaned_html)
epub_filename = "article.epub"
convert_html_to_epub(title, html_filename, epub_filename)
if os.path.exists(html_filename):
os.remove(html_filename)
return send_file(epub_filename, as_attachment=True)
if __name__ == "__main__":
app.run(host='0.0.0.0',port=5000)
Future Scope :
Fetch and Add the Blog Banner from Hashnode to pdf and ebook frontpage(coverpage).
Create a Ebook from blog series
Limitations
Emoji can't be render in PDF Doc or Ebook for now
Challenges Faced:
At first tried to use markdown and convert it to pdf but pandoc was having issue with rendering images from cdn source link for images which we get after fetching blog content.
So after research I switched to pyhtml2pdf and fetch html content instead of markdown.And during deployment on Hugging Face Spaces I faced challenge. The Container is runned in restricted mode on Spaces. So the due to permissions, the app was unable to create html file and convert it to pdf or ebook/epub.
So I used /tmp/ dir to store and convert files.Even the app was not able to convert html to pdf doc after clicking on download pdf button. The pyhtml2pdf was not able to detect chromium browser inside docker container. After cross checking converter function arguments I found I need to use install_driver=False argument.
These were the few challenges I came across while building this app.
Links :
Github :https://github.com/StarTrooper08/HashCraft/
Docker Image :
docker pull ghcr.io/startrooper08/hashcraft:main
Deploy :https://huggingface.co/spaces/StarTrooper08/HashCraft
HuggingFace :https://huggingface.co/spaces/StarTrooper08/HashCraft/tree/main
(The Hugging Face Repo has the same code as Github but made some minor changes to deploy app to HF Spaces. For example here I've used port 7860 which is default port for running docker container on HF Spaces and used /tmp dir to save html file for further process)